
需要爬取车辆的车名(奥迪)、车型(a6)、二手车价格、表显里程、上牌日期、档位(就是车的型号)、地区、车型、颜色
第一步,分析页面
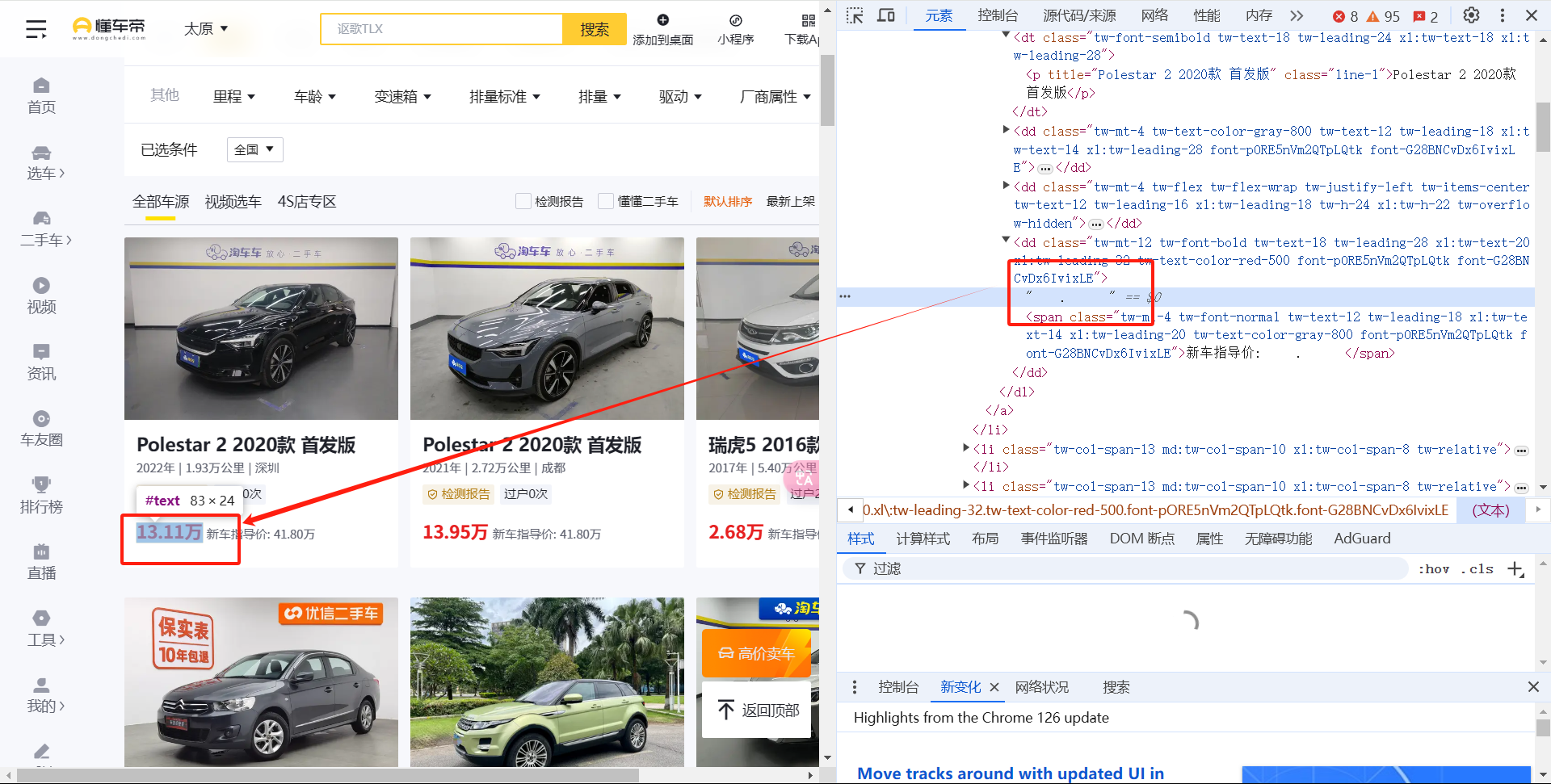
可以看到价格部分在html源码中不显示,但是在渲染好的页面上是可以显示的
这里用到了字体反爬
字体反爬简介
在 CSS3之前,Web 开发者必须使用用户计算机上已有的字体。目前的技术开发者可以使用@font-face为网页指定字体,开发者可将心仪的字体文件放在 Web 服务器上,并在CSS 样式中使用它。用户使用浏览器访问 Web应用时,对应的字体会被浏览器下载到用户的计算机上。
注:使用自动化selenium也无法获取正常的数据
在网络面板里面筛选字体
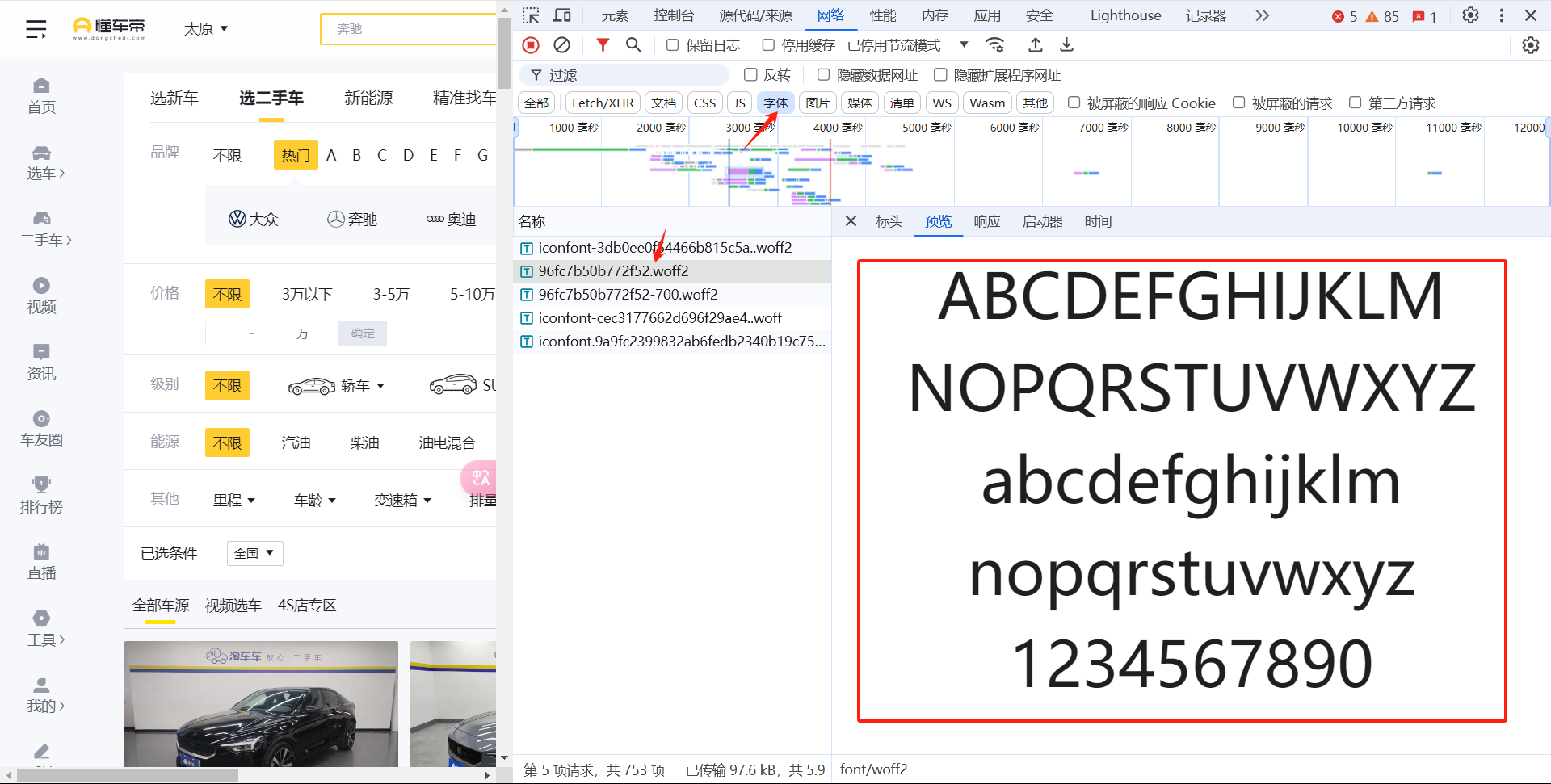
下载到本地以后使用FontCreator打开,可以看到具体的编码

现在可以将网页上无法显示的字拉到本地,看一下它的Unicode编码
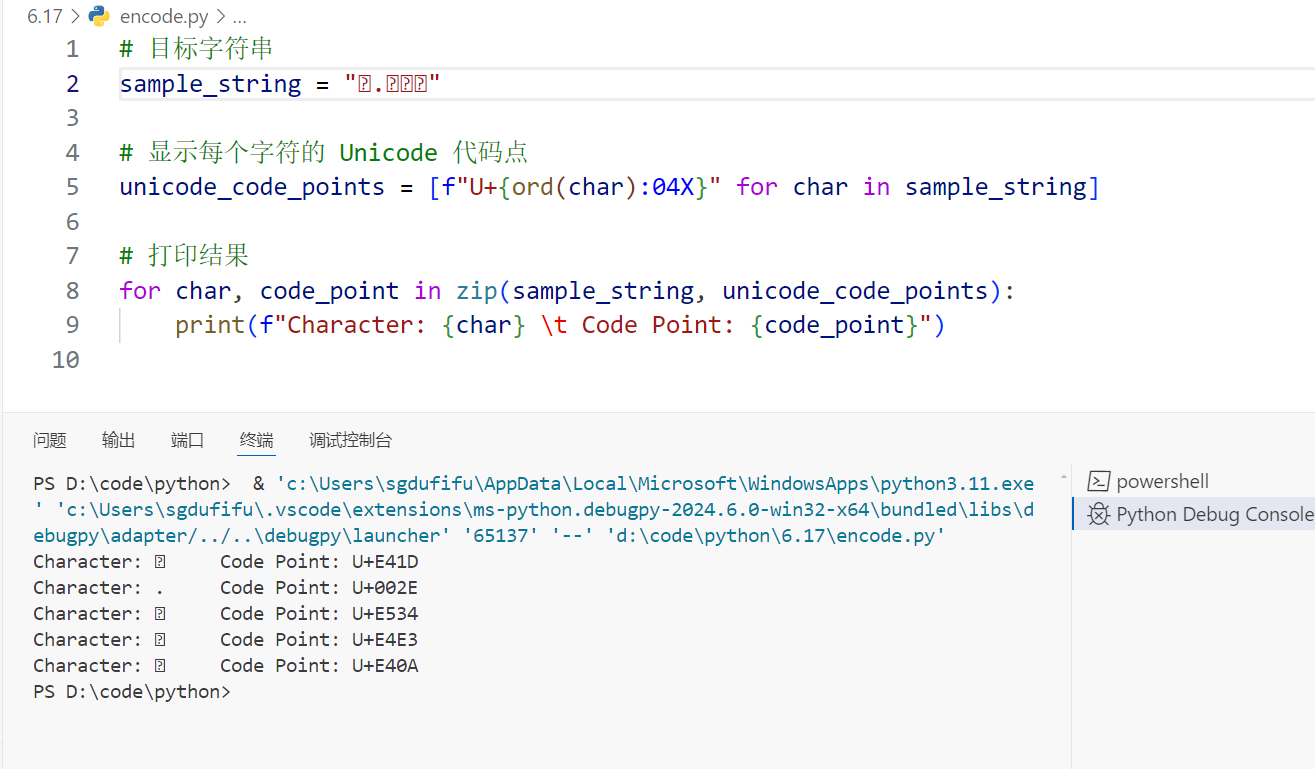
对应到上面字体文件的编码表,就可以查看到自定义的Unicode对应的字是哪个了
方便起见,使用这段代码把字体文件转为xml文件方便查找
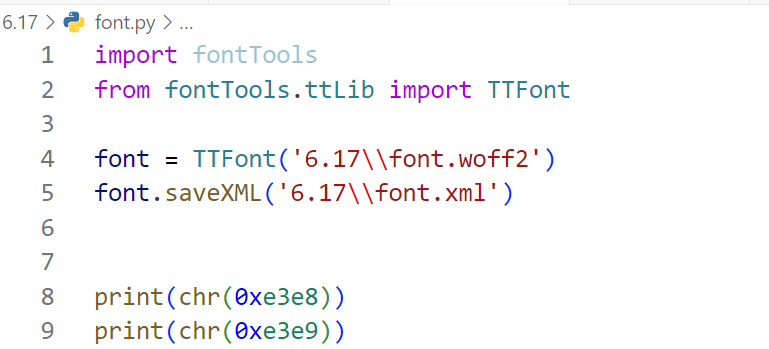
import fontTools
from fontTools.ttLib import TTFont
font = TTFont('6.17\\font.woff2')
font.saveXML('6.17\\font.xml')
print(chr(0xe3e8))
print(chr(0xe3e9))转换后输出的xml文件
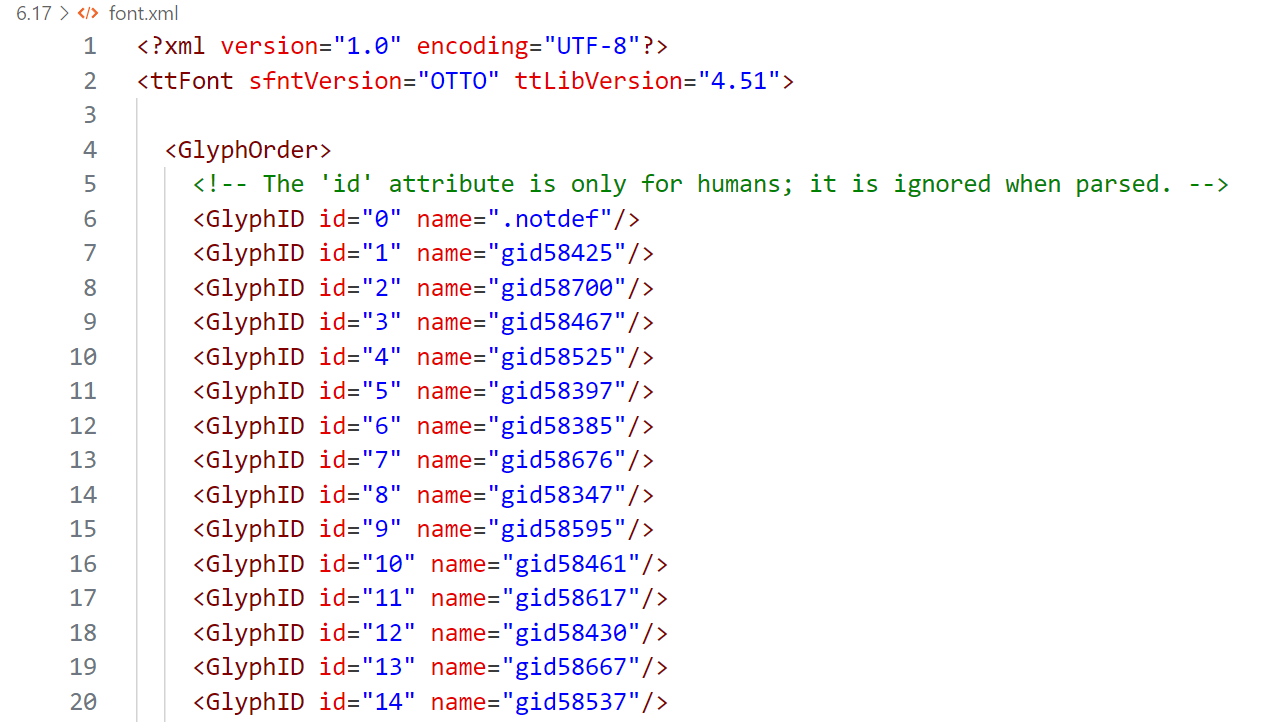
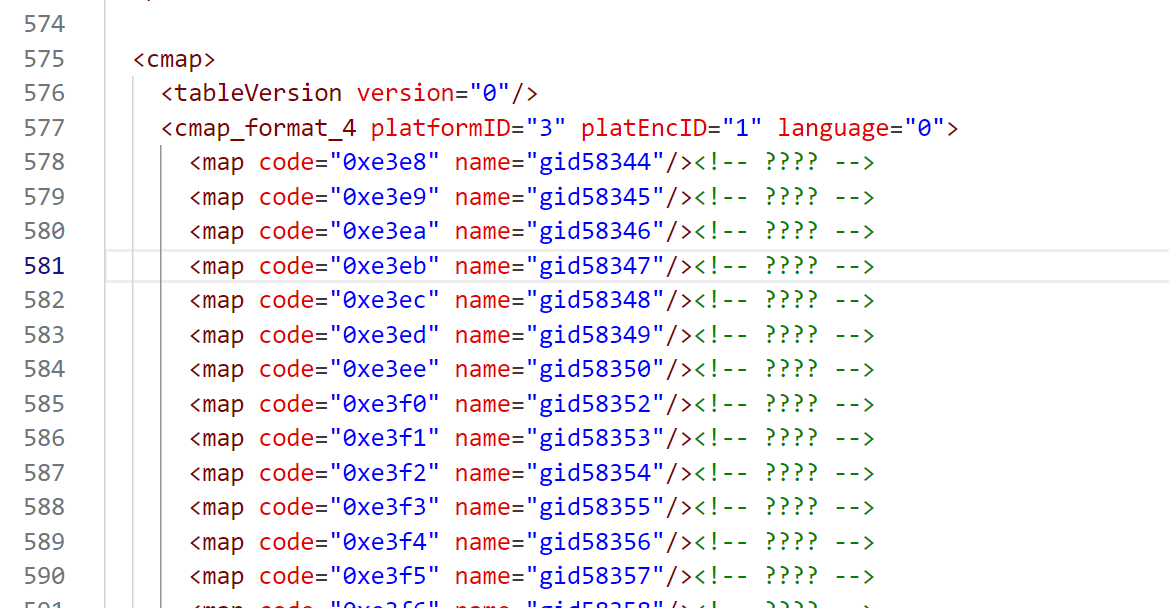
我们只需要GlyphOrder 部分和cmap部分就可以了
根据共同的元素"name"可以生成一个列表,然后再写一个替换函数
def replace_unrecognized_chars(input_str):
# 映射表,包含code和字符的映射
glyph_map = {
0xe439: '0', #
0xe54c: '1', #
0xe463: '2', #
0xe49D: '3', #
0xe41D: '4', #
0xe411: '5', #
0xe534: '6', #
0xe3EB: '7', #
0xe4E3: '8', #
0xe45D: '9', #
0xe40a: ' ', #
0xe525: '年',
0xe492: '万',
0xe4a8: '公里',
}
# 构造一个新的字符串,用于保存替换后的结果
result = []
# 遍历输入字符串中的每一个字符
for char in input_str:
# 获取字符的Unicode码点
code_point = ord(char)
# 如果码点在映射表中,进行替换;否则,保持原字符
if code_point in glyph_map:
result.append(glyph_map[code_point])
else:
result.append(char)
# 将列表转换为字符串并返回
return ''.join(result)
# 测试函数
# sh_price = '\ue4e3.\ue54c\ue4e3\ue40a'
# print(replace_unrecognized_chars(sh_price))
接下来在需要用到这些特殊字体的地方调用这个替换函数就行了
以下是完整爬虫代码
import os
import requests
from fontlist import replace_unrecognized_chars
import xlrd
from xlutils.copy import copy
import xlwt
#程序入口
def main():
#1. 爬取网页
datalist = GetData()
savepath = "6.17/dongchedi.xls"#Excel路径
#3. 保存数据
SavaData(datalist,savepath)
def GetData():
# 定义请求URL和请求头
url = "https://www.dongchedi.com/motor/pc/sh/sh_sku_list?aid=1839&app_name=auto_web_pc"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
}
datalist = []
# 定义POST请求的payload
payload = {
"sh_city_name": "全国",
"page" : "1"
}
for i in range(2): # 获取30个页面信息
payload["page"] = str(i + 1) # 更新字典中的page键的值
# print(payload)
# print(f"第{i+1}页已开始")
# 发送POST请求
response = requests.post(url, headers=headers, data=payload)
# 确保请求成功
if response.status_code == 200:
# 解析返回的JSON数据
jsonusercar = response.json()
# print(jsonusercar)
car_info_list = jsonusercar['data']['search_sh_sku_info_list']
# print(car_info_list)
for car_info in car_info_list:
data = []
brand_name = car_info['brand_name']
data.append(brand_name)
car_name = car_info['title']
data.append(car_name)
#解密未定义字符
official_price = replace_unrecognized_chars(car_info['official_price']).rstrip()
data.append(official_price)
sh_price = replace_unrecognized_chars(car_info['sh_price']).rstrip()
data.append(sh_price)
sub_title = replace_unrecognized_chars(car_info['sub_title']).rstrip()
#分割sub_title为上牌日期和公里数
parts = sub_title.split('|') # 使用'|'字符进行分割
year_part = parts[0].strip() # 去除前后的空格
registration_date = year_part.replace("里程数:", "").strip() # 去除"里程数:"前缀
data.append(registration_date)
kilometres = parts[1].strip()
data.append(kilometres)
city_name = car_info['brand_source_city_name']
data.append(city_name)
image_url = car_info['image']
data.append(image_url)
# print(data)
datalist.append(data)#追加每页信息
else:
print(f"Failed to retrieve data: {response.status_code}")
return datalist
#------------------------------------------------------------
# print(f"品牌:{brand_name}")
# print(f"车型:{car_name}")
# print(f"官方指导价:{official_price}"+"万")
# print(f"售价:{sh_price}"+"万")
# print(f"里程数:{kilometres}")
# print(f"地区:{city_name}")
# print(f"上牌日期:{registration_date}")
# print(f"图片链接:{image_url}")
# print("=" * 50)
#------------------------------------------------------------
#自适应列宽设置
def Auto_Type(datalist,sheet):
col_width = []
for i in range(len(datalist[0])):# 每列
for j in range(len(datalist)):# 每行
number1 = number2 = 0#统计字符宽度
for char in datalist[j][i]:
try:
if 0x4e00 <= ord(char) <= 0x9fff or ord(char) == 0x0020:#unicode字符集(utf-8解码)
number1 += 2
else:
number2 += 1
except Exception as e:
if hasattr(e, "code"): # 出错代码
print(e.code)
if hasattr(e, "reason"): # 出错原因
print(e.reason)
number = number1 + number2
if j == 0:
col_width.append(number)# 数组增加一个元素
else:
if col_width[i] < number:# 获得每列中的内容的最大宽度
col_width[i] = number
width = 256*(col_width[i]+1)
if width >= 65535:
width = 65535
sheet.col(i).width = width#设置列宽
#保存数据到Excel
def SavaData(datalist,savepath):
if not(os.path.isfile(savepath)):
book = xlwt.Workbook(encoding="utf-8")#创建文件
sheet = book.add_sheet("usdecar")#创建表单
Auto_Type(datalist, sheet)# type: ignore #自适应列宽
print("表格创建成功\n")
else:
rb = xlrd.open_workbook(savepath,formatting_info=True)#打开文件
book = copy(rb)
sheet = book.get_sheet(0)#打开表单
print("表格打开成功\n")
col = ["品牌","车型","官方指导价","售价","里程数","地区","上牌日期","图片链接"]
for i in range(len(datalist[0])):
sheet.write(0,i,col[i])#写入第一行
for i in range(len(datalist)):#存入数据
print("正在写入第%s条"%(i+1))
data = datalist[i]
for j in range(len(datalist[0])):
sheet.write(i+1,j,data[j])
book.save(savepath)#保存数据
if __name__ == "__main__":
#调用函数
main()
print("爬取完毕")